Transformer-based Language Models for Text Clustering
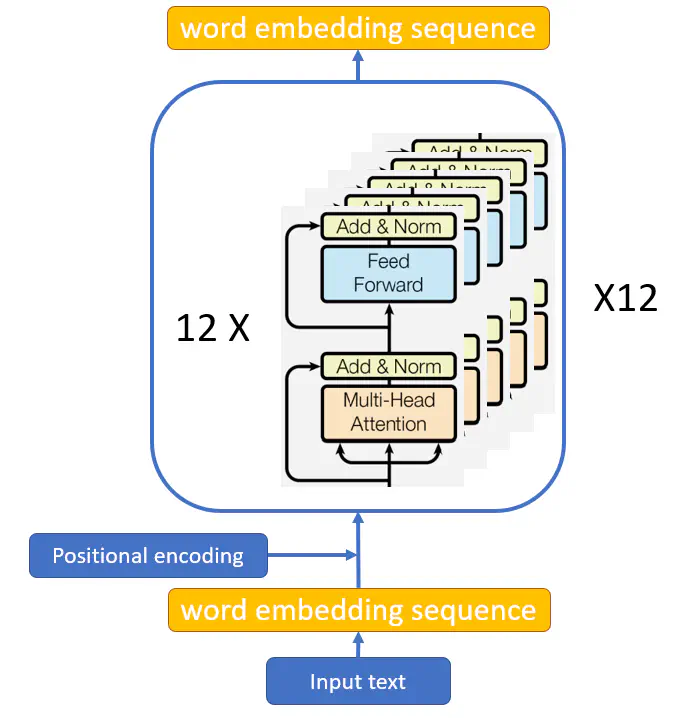 Image credit: [The structure of the base BERT model]
Image credit: [The structure of the base BERT model]Abstract
Text clustering based on probabilistic topic models has gained significant attention among political scientists in recent years. However, commonly used probabilistic topic models like Latent Dirichlet Allocation and Structural Topic Models exhibit several limitations that hinder their application. Firstly, these models struggle to accurately classify short texts. Secondly, their performance heavily relies on user decisions regarding text preprocessing and the number of clusters selected. Lastly, model training with large text datasets can be time-consuming. In this paper, I propose a workflow that uses transformer-based language models, such as BERT and GPT, for text clustering. This method surpasses traditional topic models in terms of accuracy and time efficiency. Furthermore, it reduces the impact of user decisions on text preprocessing and facilitates easy comparison of different topic numbers’ impact on research outcomes. Given the increasing popularity and application of transformer-based language models like ChatGPT, this paper encourages social scientists to explore how this state-of-the-art technology can enhance their research.
Appendix_A is an introducation of transformer-based models appendix_A. Other supplementaryappendixes.